 量子哈希
量子哈希
data = {
'a':[1,2,3],
'b':[4,5]
}
data_set = {
'a':{1,2,3},
'b':{4,5},
}
# 使用列表还是集合取决于我们自己哈
# 如果想保持元素的插入顺序就应该使用列表,如果想去掉重复元素就使用集合!!!!!
# 使用 collections 模块中的 defaultdict 来构造这样的字典
from collections import defaultdict
data = defaultdict(list)
data['a'].append(1)
data['a'].append(2)
data['b'].append(3)
print(data.items()) # dict_items([('a', [1, 2]), ('b', [3])])
data = defaultdict(set)
data['a'].add(1)
data['a'].add(1)
data['b'].add(4)
data['b'].add(3)
data['a'].add(5)
print(data.items()) # dict_items([('a', {1, 2}), ('b', {4})])# 创建一个字典
prices = {
'ACME': 45.23,
'AAPL': 612.78,
'IBM': 205.55,
'HPQ': 37.20,
'FB': 10.75
}
# 查找最小和最大的键和值
min_price = min(zip(prices.values(), prices.keys()))
print(min_price) # (10.75, 'FB')
max_price = max(zip(prices.values(), prices.keys()))
print(max_price) # (612.78, 'AAPL')
# 使用zip() 和 sorted() 函数来排列字典数据
price_sorted = sorted(zip(prices.values(),prices.keys()))
print(price_sorted) # [(10.75, 'FB'), (37.2, 'HPQ'), (45.23, 'ACME'), (205.55, 'IBM'), (612.78, 'AAPL')]
prices_and_names = zip(prices.values(), prices.keys())
print(min(prices_and_names)) # (10.75, 'FB')
# zip() 函数创建的是一个只能访问一次的迭代器
# print(max(prices_and_names)) # ValueError: max() arg is an empty sequence
print(min(prices, key=lambda k:prices[k])) # 输出最小值得键 FB
# 如果想得到键,需要在执行一次查找操作
print(prices[min(prices, key=lambda k:prices[k])]) # 10.75
'''计算操作中使用到了 (键,值) 对。当多个实体拥有相同的值的时候,
键会决定返回结果。比如,在执行 min() 和 max() 操作的时候,如果恰巧最小或
最大值有重复的,那么拥有最小或最大键的实体会返回'''
prices = { 'ccc' : 45.23, 'AAA': 45.23 }
print(min(zip(prices.values(),prices.keys()))) # (45.23, 'AAA')
print(max(zip(prices.values(),prices.keys()))) # (45.23, 'ccc')第二天坚持!!!!
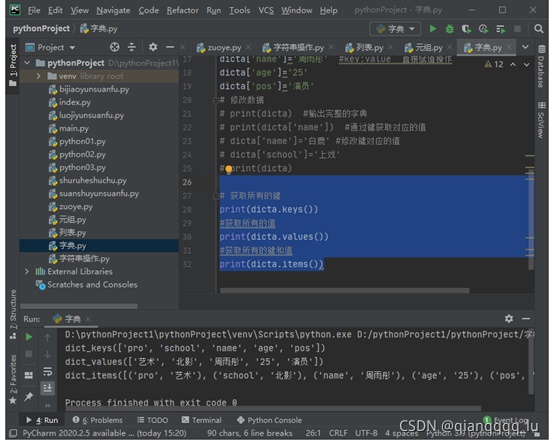
1、怎样实现一个键对应多个值的字典(也叫 multidict)? 如果一个键要映射多个值,那么需要将多个值放到一个容器中,如列表或者集合。
2、如何对进行字典进行求最小值、最大值、排序?
a = {
'x': 1,
'y': 2,
'z': 3,
}
b = {
'w': 10,
'x': 11,
'y': 2,
}
print( a.keys() & b.keys() ) # 得到相同的key {'y', 'x'}
print( a.keys() - b.keys() ) # 得到a里面b没有的key {'z'}
print( a.items() - b.items() ) # 得到a,b里面相同的key,value {'z'}
#以现有字典构造一个排除几个指定键的新字典。
print({key:a[key] for key in a.keys() - {'z','w'}})
3、查找两个字典的相同点(相同的键,相同的值)。
讨论:
一个字典就是一个键集合与值集合的映射关系。字典的 keys() 方法返回一个展现键集合的键视图对象。键视图的一个很少被了解的特性就是它们也支持集合操作,比如集合并、交、差运算。所以,如果你想对集合的键执行一些普通的集合操作,可以直接使用键视图对象而不用先将它们转换成一个 set。字典的 items() 方法返回一个包含 (键,值) 对的元素视图对象。这个对象同样也支持集合操作,并且可以被用来查找两个字典有哪些相同的键值对。尽管字典的 values() 方法也是类似,但是它并不支持这里介绍的集合操作。某种程度上是因为值视图不能保证所有的值互不相同,这样会导致某些集合操作会出现问题。不过,如果你硬要在值上面执行这些集合操作的话,你可以先将值集合转换成 set,然后再执行集合运算就行了。
来自书籍《Python Cookbook》需要资料可以留言哈!
# 利用集合或者生成器来解决这个问题
def dedupe(items,key=None):
seen = set()
for item in items:
val = item if key is None else key(item)
if val not in seen:
print(val)
yield item
seen.add(val)
a = [ {'x':1, 'y':2}, {'x':1, 'y':3}, {'x':1, 'y':2}, {'x':2, 'y':4}]
print(list(dedupe(a, key=lambda d: (d['x'],d['y'])))) # [{'x': 1, 'y': 2}, {'x': 1, 'y': 3}, {'x': 2, 'y': 4}]
print(list(dedupe(a, key=lambda d: (d['x'])))) # [{'x': 1, 'y': 2}, {'x': 2, 'y': 4}]
# 同样列表也可以通过集合或者生成器来解决问题!
def dedupe(items):
seen = set()
for item in items:
if item not in seen:
yield item
seen.add(item)
a = [1, 5, 2, 1, 9, 1, 5, 10]
print(list(dedupe(a))) # list一定要带哦 不带list生成的是一个对象
print(set(a)) # 如果只想去除重复可以直接用set()
‘’‘
读取一个文件,消除重复行,也可以用这样的方法
‘’’
with open(file,'r') as f:
for line in dedupe(f):
print(line)












