 量子哈希
量子哈希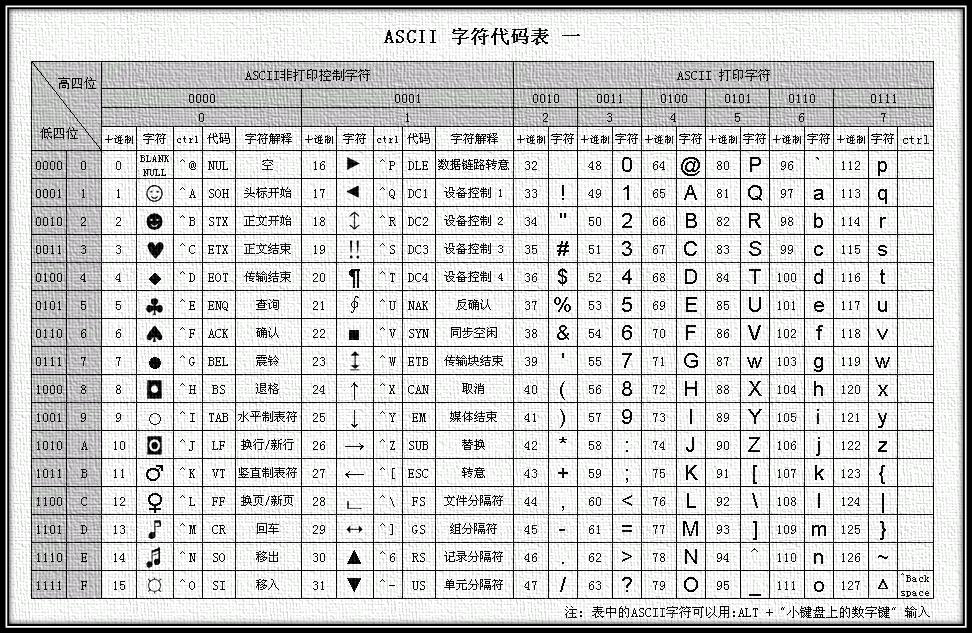
字符集和字符编码是软件开发人员必须掌握的重要知识。您可能遇到过打开网页时显示乱码的情况。您还记得HTTP中的Accept-Charset、Accept-Encoding、Accept-Language、Content-Encoding、Content-Language等消息头字段吗?接下来,我们将探讨这些内容。
目录:
3.Unicode字符集&UTF编码
4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language
5.参考文献&进一步阅读
1.基础知识
计算机中存储的信息是用二进制表示的,而我们在屏幕上看到的字符是二进制转换后的结果。字符集是系统支持的所有字符的集合,包括各国文字、标点符号、图形符号和数字等。字符编码是一套规则,用于将字符与数字系统进行配对,以便计算机能够识别和存储各种字符。
2.常用字符集和字符编码
常见的字符集包括ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集和Unicode字符集等。为了准确处理各种字符集的文字,计算机需要进行字符编码。
2.1. ASCII字符集和编码
ASCII是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语。ASCII字符集包括控制字符和可显示字符。ASCII编码将字符集转换为计算机可接受的数字系统的规则。ASCII字符集映射到数字编码规则如图1和图2所示。
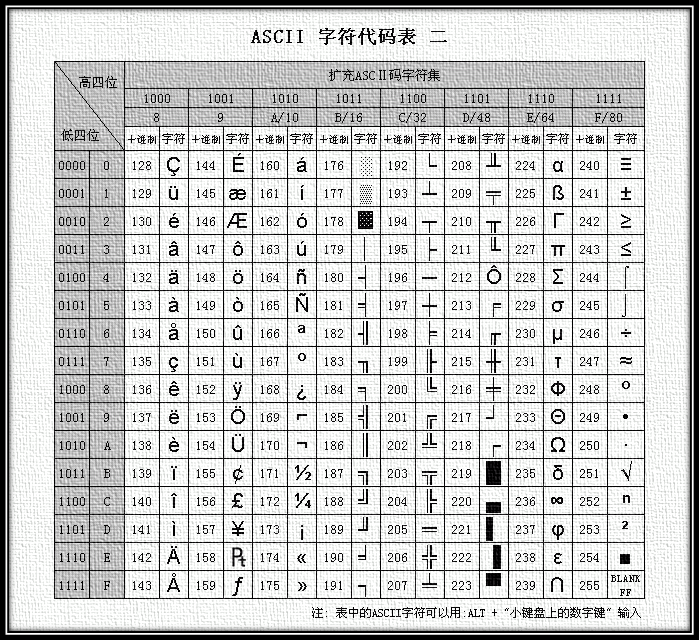
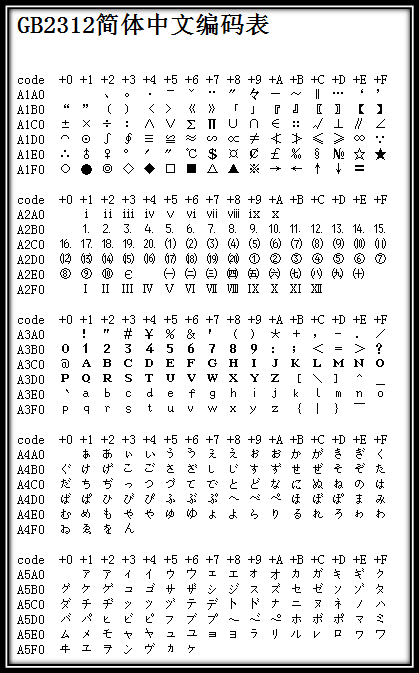
图1 ASCII编码表
图2 扩展ASCII编码表
2.2. GBXXXX字符集和编码
为了显示中文,计算机需要设计一套编码规则。GB2312是中国国家标准简体中文字符集,收录了约7000多个简体汉字。GB2312的出现基本满足了汉字的计算机处理需求。后来,GBK和GB18030汉字字符集相继出现,以处理罕用字和其他语言的汉字。
2.3. BIG5字符集和编码
Big5是使用繁体中文最常用的字符集标准,收录了13060个汉字。它是双字节字符集,使用两个字节来存储一个字。
3.Unicode字符集和UTF编码
为了解决不同字符集之间的兼容性问题,Unicode编码系统应运而生。Unicode使用4字节的数字来表示每个字符,可以表达任意语言的任意字符。UTF-32、UTF-16和UTF-8是Unicode的三种字符编码方案。
3.1. UCS和Unicode
通用字符集(UCS)是ISO制定的标准字符集,而Unicode是基于UCS的标准字符集。Unicode采用了与ISO 10646-1相同的字库和字码。
3.2. UTF-32
UTF-32是一种将Unicode字符编码的协定,对每个字符都使用4字节。它在定位特定字符时具有常数时间复杂度,但空间效率较低。
3.3. UTF-16
UTF-16是一种将Unicode字符编码的协定,对于大多数字符使用2字节编码,对于超出范围的字符使用特殊技巧。
3.4. UTF-8
UTF-8是一种可变长度字符编码,可以表示Unicode标准中的任何字符。它兼容ASCII字符,并在空间效率和处理中文字符方面具有优势。
4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language
在HTTP中,与字符集和字符编码相关的消息头字段包括Accept-Charset、Accept-Encoding、Accept-Language、Content-Type、Content-Encoding和Content-Language。
Accept-Charset是浏览器声明接受的字符集;
Accept-Encoding是浏览器声明接受的编码方法;
Accept-Language是浏览器声明接受的语言;
Content-Type是服务器告知浏览器响应对象的类型和字符集;
Content-Encoding是服务器表明使用的压缩方法;
Content-Language是服务器告知浏览器响应对象的语言。
通过这些消息头字段,浏览器和服务器可以进行字符集、编码和语言的协商和匹配。













