 量子哈希
量子哈希
博客:oschina、云+社区、知乎等各大平台都有。 目录一、列表推导式 推导式可以帮助我们快速创建列表、创建字典。比如现在要创建一个列表。 做自动化测试的时候,比如创建个 url 列表,url 列表里面可能是存储了网站的页数:
# url = ['page1','page2']
urls = []
for i in range(1,101):
url = 'page{}'.format(i)
urls.append(url)
print(urls)
一直到 100,生成 100 个页面,但是这 100 个页面有规律,url 地址,前面这一部分是不变的,只有后面的 1,2,3,4 这部分的变化。 如果去生成这样一个列表,不用列表推导式,用之前的方法的话,可以这样做,先定义一个空列表: urls = [] 然后来个 for 循环 set 100 个: for i in range(1,101): 前面字符串这部分是确定的,比如说一个 page,后面这部分不确定,就来个format()给它填进去。 url = ‘page{}’.format(i) 通过append()把 url 加进去。
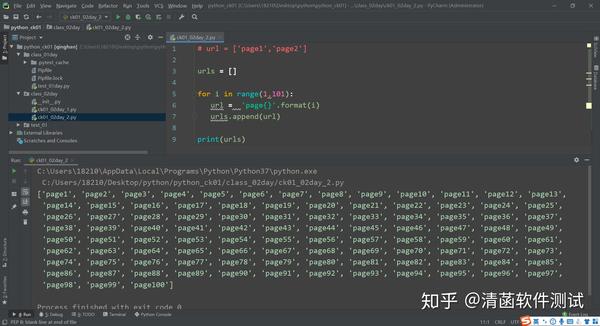

# 列表推导式
urls1 = [i for i in range(1,101)]
print(urls1)
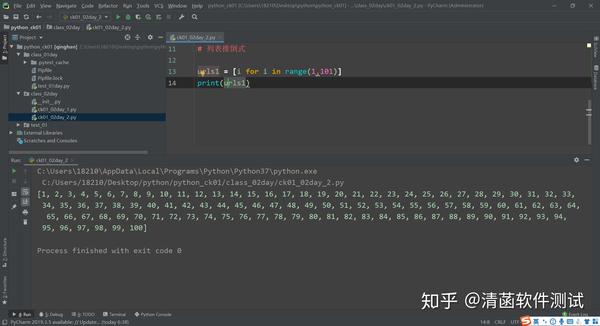
能够生成 1-100 个页面。 推导式有个优势,一行就能解决。推导式可以看成 for 循环的一个解体。 写起来特别简单,同样的功能,推导式可以这样写: 这段列表推导式代码解释是: for 循环,i 从 range 里面循环,循环出来拿出一个 i,然后往前面放到这个列表里面。 再拿出一个 i 放到这个列表里面,这样重复(拿出一个 i 放到列表里面),直到把 for 循环遍历完。 将里面所有的元素都拿出来放到列表里面,最后生成一个新的列表,这就是列表推导式。 里面是 1-100 个数字:
urls1 = ['page{}'.format(i) for i in range(1,101)]
print(urls1)
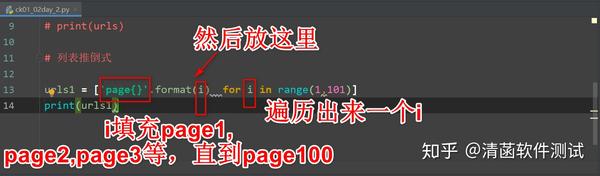
# 列表推导式
urls1 = ['page{}'.format(i) for i in range(1,101)]
print(urls1)
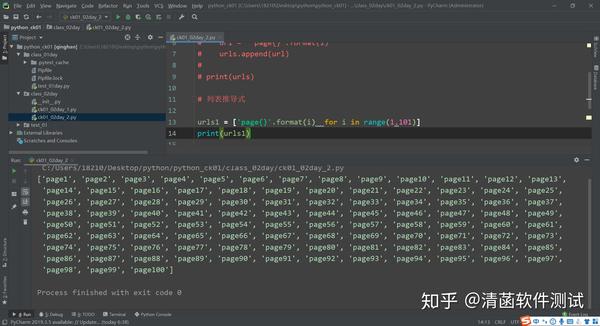
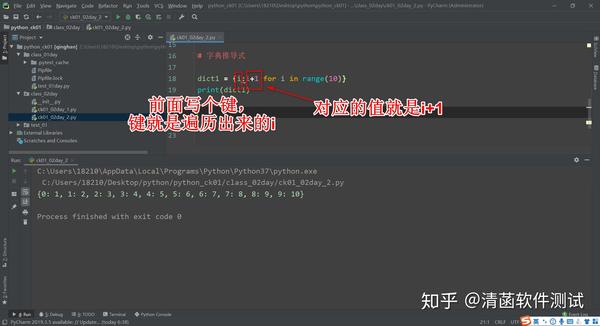
如果用列表推导式生成这个 page1,到 100 页。代码就修改成这样: ‘page{}’.format(i) format()格式化字符串的函数。 简而言之,就是遍历出来的元素放到这个前面就行了。然后在前面,你可以做其它操作。 以上,这就是用列表推导式快速生成一个列表。 二、字典推导式 字典推导式和列表推导式,它的原理是一样的。都用 for 循环去遍历,然后拿出对应的值在前面,生成对应的值。 每遍历一轮,会把前面你写的内容放到字典里面去。前面写个键,键就是遍历出来的i,对应的值就是i+1。
dict1 = {i:i+1 for i in range(10)}
print(dict1)
# () 生成器表达式
tu = (i for i in range(10)) #生成器对象
print(tu)
键就是遍历出来的i,值就是键的基础上加 1。每循环遍历一轮,这个就生成一个键值对。 推导式可以推导出字典,也可以推导出列表。大括号、中括号、花括号都可以。 推导式改成小括号后是什么? 中括号是列表,花括号是字典,小括号是元组。 推导式改成小括号后,不再是个元组了,是个生成器。
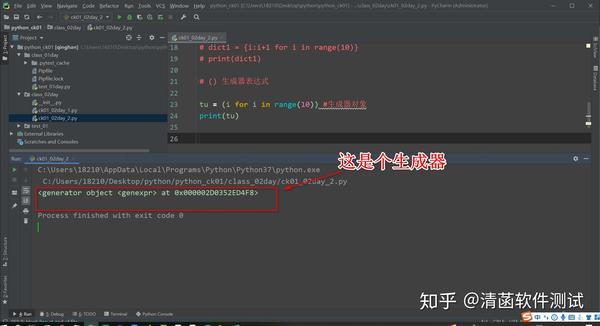
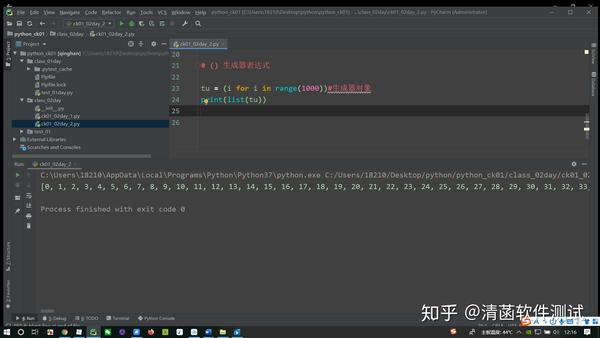
三、2种方式创建生成器1.生成器表达式1.1 什么是生成器? 这里有很多数据,可以把它装到一个 “就像自动取筷盒,拿出一双筷子,自动下来一双筷子”,就是你要用的时候,它给你生成一个出来。 生成器不像列表,比如创建个列表,比如列表里面有一千个元素,创建列表的时候,那么这一千个元素已经被创建好放在列表里面了。生成器不是这样,它内部只保留了一个生成器计算的规则。 1.2 使用生成器的好处生成器要生成一千个元素,这样: tu = [i for i in range(1000)]#生成器对象 直接生成一千个元素的列表。改成生成器,这个生成器对象里面存储的是一个计算公式,并没有存储这一千条数据啊。 使用生成器来存储这些数据的话,相对于列表的优势是:不那么占内存。 一千条数据可能看不出效果,如果是一千万条数据往列表里面一放,那得占用多大的内存啊。如果是个生成器,里面就是个计算的规则,就是个生成的规则,没有那么多数据,节约内存,可以提高代码的性能。 1.3 拿生成器里面的数据,也可以一个一个得拿,怎么拿呢? 生成器表达式,打印出来是个生成器。
tu = (i for i in range(1000))#生成器对象
print(list(tu))
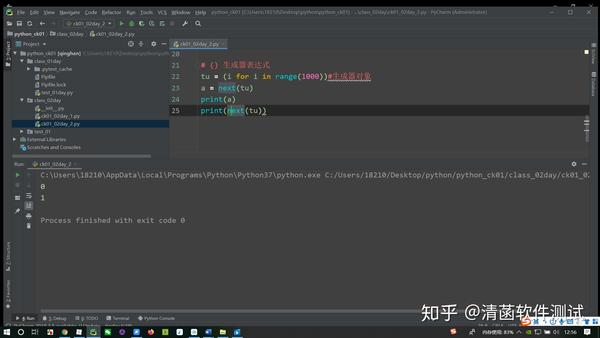
# () 生成器表达式
tu = (i for i in range(1000))#生成器对象
a = next(tu)
print(a)
print(next(tu))
当然,可以通过list把它转换成一个列表。 它可以把生成器里面所有的元素都拿出来转换成列表。 通过生成器表达式来定义生成器,一次想拿一个元素,怎么拿呢? Python 里面有个内置的函数,叫做next()。把生成器对象放进去,得到一个结果:
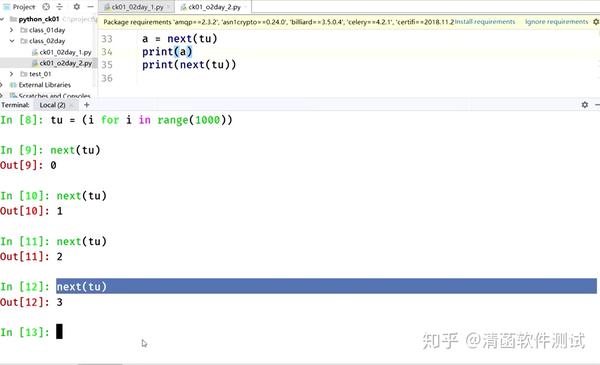

交互环境中可以看到: 它依次生成,要的时候,从生成器里面拿一个出来就行了。你要用的时候就去拿,它就一直生成,它就把里面所有的元素都取出来。 1.4 所有的元素都取出来之后,我又拿了一次,它会出现什么情况呢?
def gen_fun():
print('清菡 加油')
gen_fun()
会报错。 生成器可以用来节约内存,提高代码性能。生成器在于你什么时候用,你什么时候去取值。 2.函数里面,通过 yield 定义生成器 除了生成器表达式可以创建生成器,还有另外一个方式。Python 关键字里面有个yield参数。 yield这个关键字是用在函数里面的,这个关键字只能在函数里面用。 函数定义完之后,只要在函数里面调用函数,那就会执行函数里面的代码。
def gen_fun():
yield
print('清菡 加油')
gen_fun()
def gen_fun():
# yield
print('清菡 加油')
res = gen_fun()
print(res)
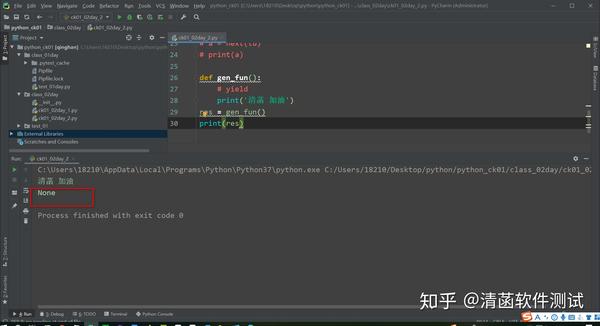
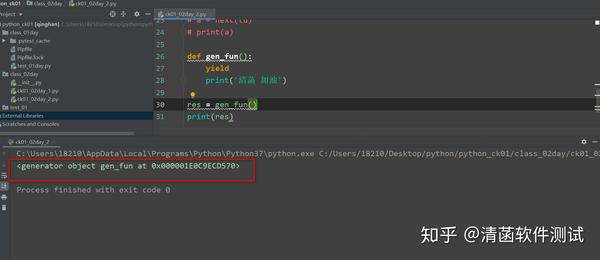
如果当一个函数里面,有yield这个关键字: 这个时候再去运行这个函数,这个函数不会立即运行。 2.1 为什么不会立即运行呢? 这个函数运行的时候,默认是没有写return的。 如果函数里面出现了yield这个关键字,这个时候再看下。 函数没有写return,调用函数,它里面,代码没有执行,但是有返回结果,返回的结果是:
# 通过yield定义生成器
def gen_fun():
yield
print('清菡 加油')
res = gen_fun() #返回生成器对象
print(next(res))
返回的是一个生成器。 通过yield定义出来的这个函数,是个生成器函数。 调用这个函数的时候,它会给你返回一个生成器对象。既然它是一个生成器对象,那么就可以通过next()来对它进行取值。 运行结果如下:
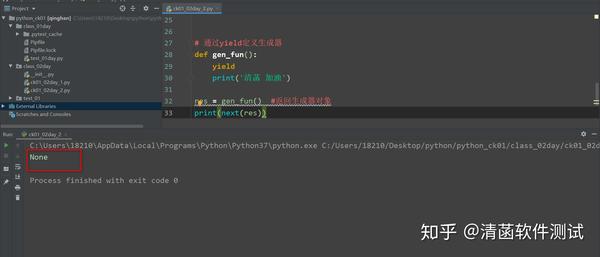
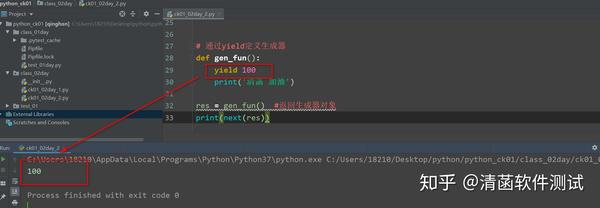
# 通过yield定义生成器
def gen_fun():
yield 100
print('清菡 加油')
res = gen_fun() #返回生成器对象
print(next(res))
# 通过yield定义生成器
def gen_fun():
yield 100
print('清菡 加油')
yield 1000
yield 100100
res = gen_fun() #返回生成器对象
print(next(res))
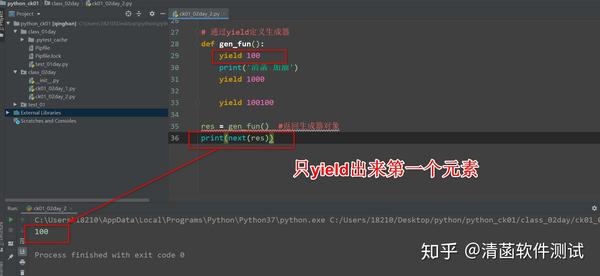
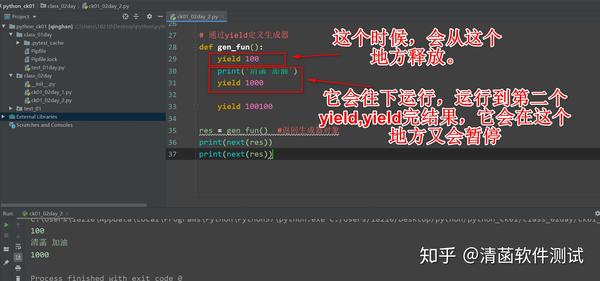
你看到输出结果是:None 2.2 为什么是 None 呢? 生成器生成的元素在yield关键字后面。 再写 2 个yield: 生成器函数: 只有通过next()取值的时候,它才会执行函数里面的代码。 next()一次,就运行到第一个yield这里,把这个结果返回出来。然后到这个地方,暂停了不动了,不会往下走了。 如果在下面再next(),从生成器里面再获取一个元素: print(next(res))
# 通过yield定义生成器
def gen_fun():
yield 100
print('清菡 加油')
yield 1000
yield 100100
res = gen_fun() #返回生成器对象
print(next(res))
print(next(res))
print(next(res))
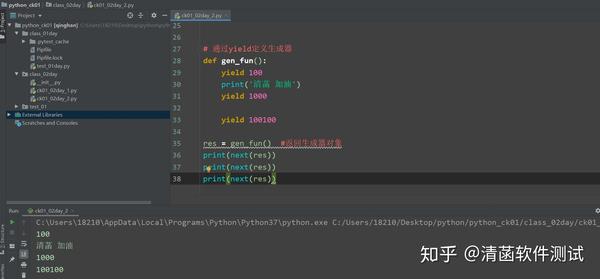
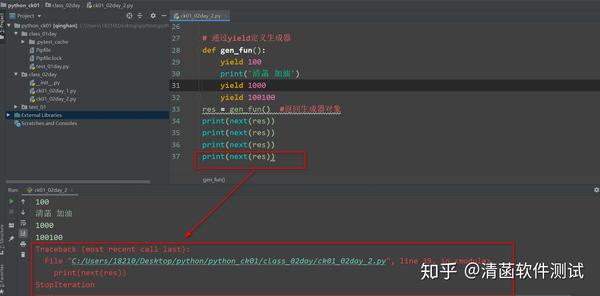
直到等到下一个next()取值。当你下一次从生成器函数里面取值的时候,才会触发下一个yield。 但是如果全部都生成完了,再去取一次,就会报错: 因为里面已经没有元素了。 以上,生成器只有通过这 2 种方式定义。 公众号 「清菡软件测试」 首发,更多原创文章:清菡软件测试 108+原创文章,欢迎关注、交流,禁止第三方擅自转载。













